The internet economy has been driven by a business model that offers services for free to the end users, but at the same time creates profits by mining, aggregating, and selling personal data (shopping habits, browsing history, location data, political affiliations, demographics, and so on). Over the years, the economic and social value of personal data has accrued to a small number of large tech companies who control the flow and use of that information.
In our recent workshop, we asked our attendees to imagine a more equitable vision of the internet economy, including how they might manage their personal data in 2030. For example, will people be using their data to earn a steady income, will they be sharing it for the common good, or will it be out of their hands as it circulates around a global internet economy?
Some of the ideas people came up with included burner personas, data unions, and technologies for data sovereignty. This introductory blog summarises the key themes and challenges that emerged from the presentations and scenario planning exercises. We start by describing the methods that we used for our interactive session.
Overview of the workshop
At the workshop, participants were asked to imagine how the personal data economy could look in 2030, and how a range of different people might engage with that scenario. In the first exercise, a range of drivers were given, with each group receiving a ‘wild card’ assumption that changed one of those drivers.
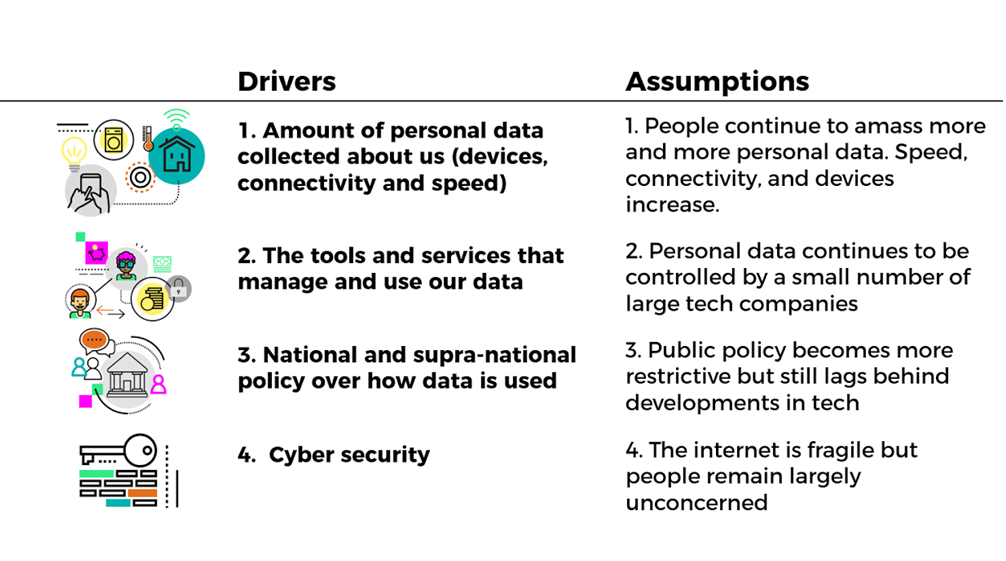
Image: drivers and baseline assumptions about the future of the personal data economy
Accompanying this was also a set of broader trends, such as the Internet of Things (IoT), artificial intelligence or demographic change. Each group was asked to consider how this wild card would change the supply and demand of data in the future, how value would be extracted from data and how society would feel about it.

Image: each scenario was situated on an X axis of pessimistic to optimistic and Y axis of plausible to implausible
In the second half, participants were asked to imagine a person living in this scenario, and to storyboard them undertaking key activities.
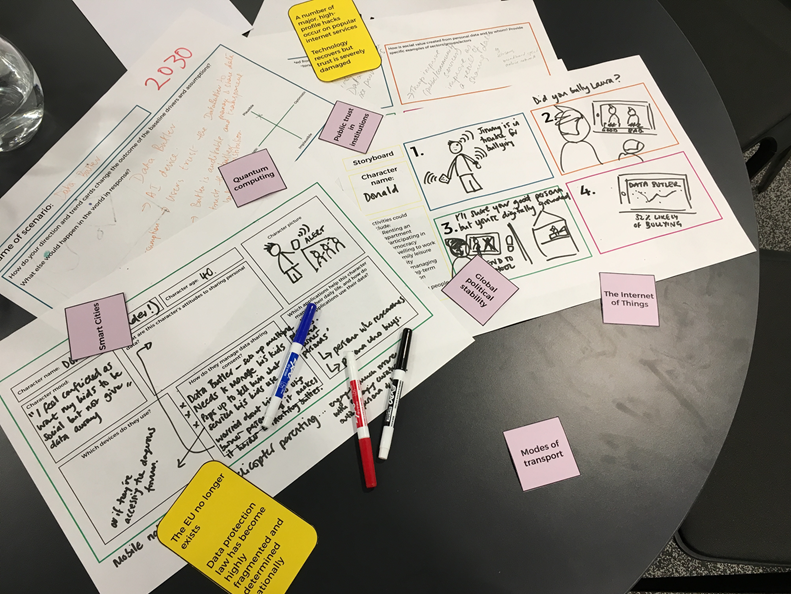
Image: yellow wildcards and a storyboard of “data butler”, one of the scenarios created at the workshop
Below, we have summarised the five key themes that emerged from the workshop activities.
The nature of privacy is changing
Giving people control over their data will require building new technology infrastructures that respect their right to privacy. Many platforms today practice surveillance by design, whereby metrics and behaviour tracking algorithms are a central part of how software extracts value from users.
This has the potential to pose a greater breach of privacy as more of our surroundings are digitised. The IoT market is projected to produce approximately three billion new connected devices every year, each of which have sensors with the potential to collect sensitive or personal information.
In response, we heard several alternative versions of the future related to online identity. In one example, people could use ‘burner’ identities that allow them shed unwanted online selves and potentially start afresh. Others spoke about the potential for pseudonymous interaction online. In a pseudonymous identity system, identities could be verified, but the privacy-preserving infrastructure would only reveal the minimum information necessary to that interaction. For example, technologies such as attribute-based credientials might allow a customer to prove to a vendor that they are over 18, without the need to reveal their age or any other personal information.
New economic models, however, began to throw these scenarios into question. The so-called sharing economy relies on attaching fixed identities and reputations to both people and physical things, blending the division between people’s offline and online lives. This raised new questions about whether some loss of privacy will be a necessary precondition for participation in the future labour market.
Who owns the data exchange infrastructure?
Many scenarios developed during the workshop presented the benefits of personal data stores, including a potential open ‘exchange’ that allows people to manage, audit and donate data on their own terms. Opening up the exchange for personal data would improve competition, and would see the emergence of new insights from that data, creating new forms of social value.
Examples like Datacoup and Give With Data provide people with layered insights about their behaviours, as well as more say over where the economic value of their data should go (either to be pocketed by the user or donated to charity); whereas Citizenme gives people the chance to provide anonymous insights from their data directly to charities or other organisations for social research.
But as Irene Ng raises in her blog contribution to this series, this leads us to still unanswered questions about who maintains and designs such a system. Governments, venture capitalists, not-for profits and universities are all offering their own privacy-preserving data stores, but few are talking enough about governance models, or how subtle differences in the design of these systems could benefit certain groups over others.
The potential for cooperative models, complemented by blockchain-inspired technologies, was discussed during our workshop. These would help shift the governance structure from one that is centrally owned and maintained, to one which embeds a collaborative form of ownership over the digital platform and the (personal) data generated by it.
Initiatives include the Sovrin Foundation, a ‘self-sovereign identity’ platform with a federated governance model; The Good Data; or Midata.coop which make users full stakeholders in how sensitive data is used or who it is shared with. These examples aim to reduce the political friction of one central authority or group acting as a single controller of the digital infrastructure.
A new geographical landscape of data commons
This led us to imagine new spatial patterns about how data is stored and managed in 2030. The desire for a more democratic governance over personal data naturally led people to imagine a local ‘cottage industry’ of platforms that collaborate and pool data, either for use cases in specific communities or cities.
For example, we heard about data unions and data cooperatives that might be locally governed, where individuals donate their data to obtain local sharing economy services (like sharing childcare arrangements, health data to inform research, or ‘FairBnb’ type services for accommodation). Personal data is collected and exchanged by these platforms, and managed democratically and on the basis that it benefits the aims of the cooperative.
Opinions about the feasibility of this scenario were mixed. Often the value in personal data is only possible due to its collection in very large volumes, so there was a suggestion that public opinion would have to considerably shift before there are enough people who want to use these services. Nonetheless, seeds of change are emerging in the form of the global platform cooperatives movement.
There are legal and practical barriers to ‘owning’ your personal data
Many people were in agreement that platforms can be designed to make the user the legal owner of their data, that is, the user becomes the data subject and the data controller. Personal data stores are already doing this, and they offer this as a service to organisations that increasingly see the management of personal data as a liability in the context of strict European regulations.
However, the challenges to truly ‘owning’ data are well known. This is partly a definitional problem. The boundary between what could be deemed ‘anonymous’ or potentially ‘re-identifiable’ data is contested.
But owning your data is also a practical challenge. Nowadays data collection of all kinds is so pervasive that it does not seem feasible for any individual to be able to track the full extent of their digital footprint, or to claim it as their own. Even if individuals could be reasonably expected to claim ‘some’ of their data, there is still the issue that data is a non-excludable asset - if it is shared once, or if it falls into the wrong hands, it can be replicated infinitely and quickly detached from the original subject's intentions.
In response to this issue, one group raised the issue of data standards. In the future, there may be specific data licenses that make much more granular consent management possible. When a user shares their data, they may do so with specific entitlements or rules attached to it (e.g. this data may only be used for non-profit purposes, or for ‘X’ amount of time). These may be machine-readable, and make it much easier for both individuals and data processors to comply with user consent.
As Reuben Binns writes in his blog contribution, efforts to create interoperable privacy standards are not new; the key challenge has been in adoption. Companies whose business model depends on ‘locking in’ their customers have a vested interest in avoiding wider use of standards that improve data portability.
There may be unintended consequences with greater user ownership
There are further, related problems with arguments about ‘owning’ data, including possible unintended consequences associated with giving people more control. As with any policy or programme, the way it will interact with the complex dynamics of the real world can never been known in advance.
Privacy advocates and technologists too often assume that members of the wider public are as capable or as rational as they are in their privacy behaviours. For instance, there is evidence to show that giving people greater control may lead to an even more lax approach to how they share their data.
On the other hand, some authors paint a picture where, given full control, people's rational response may be to completely restrict any external access to their data. This could be a potentially harmful outcome in contexts where sharing that data might be able to deliver significant public benefit (e.g. where personal education or health data might be used for academic research).
There were a handful of responses to these challenges in the scenarios constructed during our workshop. These included better policy to help protect and inform vulnerable data subjects (including a stronger approach to promoting data literacy), as well as the development of privacy tools with better user design.
Sarah Gold’s contribution reinforces the latter point. She uses the example of Pretty Good Privacy, which allows people to send encrypted emails. PGP is an important tool, but can be difficult for even technically-accomplished people to understand how to install or use it. A first step in any solution should be to work closely with users to design tools around their privacy behaviours. Bad design is too often used to confuse or manipulate people’s behaviours.
Although it’s usually only the dominant players who are able to invest the most time and resources into elegant user design, Sarah points to some promising outliers.
The DECODE project
The task of DECODE over the next three years will be to design a system that can respond to these questions and concerns.
Through research and a series of practical pilots in Barcelona and Amsterdam, the project aims to explore the potential for people to control and share their data for the public good. The ultimate vision is one of a digital commons: internet platforms as shared, locally-owned resources, whereby the rules ensure that the exhange of personal data remains under democratic control of the users.
Follow us on Twitter for more updates @decodeproject
This blog was originally posted on the Nesta website as part of a blog series: The Tug of War Over Personal Data
 DECODE was funded by the European Union's Horizon 2020 Programme, under grant agreement number 732546.
DECODE was funded by the European Union's Horizon 2020 Programme, under grant agreement number 732546.